4月3日19时,“云端锦江”系列讲座第十三场通过腾讯会议平台顺利举行。新加坡南洋理工大学心理学副教授邱林应邀作“大数据时代社会科学研究的新方法”的主题讲座,我院陈侠副教授任主持人,院内外198名师生在线参与,并与邱林副教授交流讨论。
主讲人简介

邱林,新加坡南洋理工大学心理学副教授,美国西北大学博士。多次在《心理科学》、《人格与社会心理学公报》、《人格研究期刊》、《计算机与人类行为》、《计算社会科学期刊》、《网络心理行为与社交》等权威期刊上发表论文。现为国际期刊《计算社会科学杂志》副主编和《亚洲社会心理学杂志》副主编。
本次线上讲座中,邱林副教授介绍了田野研究等传统社会科学研究方法及其在大数据时代所经历的演变。同时,邱林副教授还结合具体研究案例演示了这类方法与技术如何丰富我们对人类行为的洞悉,例如,如何理解人们对新冠疫情期间封锁政策的不同反应。

大数据时代的社会科学研究方法
邱林副教授首先回顾了实验室实验(Laboratory Experiments)、实验模拟(Experimental Simulations)、田野实验(Field Experiments)、抽样调查(Sample Surveys)、计算机模拟(Computer Simulations)、 田野研究(Field Studies)等八种常见的社会科学研究方法。他认为,这些研究方法各有利弊,因此需要采用不同方法研究同一问题,从而弥补不同方法之间的缺陷。邱林副教授指出,数字化信息和计算能力的激增催生了计算社会科学这一新兴领域,而大数据力量的汇入致使研究样本量扩大,这对研究者在数据挖掘、网页抓取等方面的能力提出了更高的要求。在此基础上,邱林副教授详细演示了各种研究方法在具体案例中的过程及方法。
邱林副教授以Science上的一项用百万数字化图书对文化进行定量分析的研究为例,详细阐述了大数据如何被应用到田野研究中。在介绍该项研究时,邱林副教授就如何利用Google Books Ngram Viewer查询书本中的关键词在不同年代里的出现频率进行了示范,并指出此类技术为数据分析提供了更多有趣的可能性。
其后,邱林副教授还对LIWC这一文本分析工具进行了详细演示。LIWC(语言探索与字词计数)是20世纪80年代Pennebaker等人在研究情绪书写的治疗效果时发明的基于计算机软件程序的文本分析工具,是一种可以对文本内容词语类别(尤其是心理学类词语)进行量化分析的软件,具有良好的信效度。邱林副教授以自己的一项有关“认知的节律性(Temporal Pattern of Cognition)”的研究为例,该项研究将新加坡和旧金山的推特使用者在八个月内发布的推特作为研究样本,通过测量样本中所包含的六种问题(who,what,when,where,why,how)及其在时间更迭上的差异性,阐释认知的节律性在两国推特用户中的表现异同。
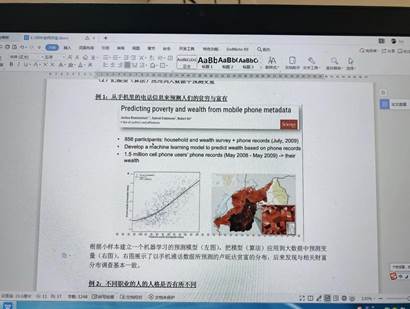
邱林副教授提醒同学们关注未被注意的变量(Study Unobserved Variable)。他指出,可通过采集小于1000的小样本数据开发机器学习模型,并将模型应用于大数据研究中,以此预测变量间的关系。邱林副教授以学术期刊《Science》上的一项根据移动电话的数据来预测经济状况的研究为例,展示大数据时代小数据的潜在研究价值。此外,《美国科学院院报》(PNAS)的一项研究也体现了小数据的大价值,该研究根据1035名推特用户的社交媒体使用情况预测其性格特征和价值观,勾画出不同职业的人格画像。
邱林副教授
从大数据推断因果关系
邱林副教授展示了如何用大数据揭示出隐含的事物因果关系(Causal Inference)。他通过分析“听讲座与成绩好之间是否存在因果关系”、“宅和厨艺好是否存在因果关系”,对随机实验(Randomized Experiment)中的因果推论进行演示,并以《美国科学院院报》(PNAS)上关于社交网络大规模情绪感染的实验研究为例,进一步对随机田野实验方法进行推导和说明。他也举例说明了如何利用大数据的多维度和完备性来结合随机事件进行自然实验(Natural Experiment),通过对信息的挖掘、加工和匹配,来推断因果关系。

同学笔记
大数据研究中常见的问题
邱林副教授用一个利用短信来研究9/11后情绪变化的研究为例,说明大数据研究中可能出现的陷阱。他强调,在利用大数据进行研究时,须注意数据分析的第一步——数据清理(Data clean),严谨检查数据质量,排除数据中的“噪音”,从而为得出真实可靠的研究结果奠定基础。
随后,他介绍了发表在《Nature》上的一项使用搜索引擎获取数据监测流感疫情的研究。该研究指出,相较于CDC(疾病控制中心),基于谷歌搜索的算法能更快更准地预测流感疫情。但2014年《Science》上的一项研究则揭示了谷歌预测流感背后所隐藏的大数据分析陷阱,该研究一针见血地指出机器模型过度学习(Model Over-fitting)的问题所在。
最后,邱林副教授总结道,当前的社会科学正在经历一场前所未有的历史性变化,在面对大数据所提供的大量研究机会的同时,研究者应当时刻保持“谨慎的乐观”。
讲座结束前,同学们就学术研究过程中遇到的问题与邱林副教授进行了探讨,线上互动区学术氛围热烈。
线上互动
感想与收获
2017级网络与新媒体专业本科生常同学:
作为一名社科生,我们一方面正强烈地感受到新传学科范式发生的革新,另一方面又受限于理解数据和运用技术的能力。邱老师的讲座正是结合非常丰富的案例,介绍了计算社会科学的技术和方法。从性别词频分析、LIWC工具的运用、认知节律性变化等一系列研究中,我既感受到了“数据驱动”下,从现象提取规律的便捷性和可靠性;又认识到了“理论驱动”下,对算法和技术不能丢失的反思和警惕,正是在这样“谨慎的乐观”的平衡中,研究才能避免落入工具理性主义的陷阱。
2018级新闻学专业本科生潘同学:
邱老师运用“方法+实例”的方式,从样本选取、方法比较,到大数据应用、建模,清晰详尽地为我们展示如何将大数据融入相关性检验、因果关系推断等方法之中。邱老师还给我们介绍了大数据分析常用软件,同时提示我们在运用大数据进行科研时要保持警惕,例如数据收集后要进行“data cleaning”。总之,这堂讲座让我们人文社科的同学获益匪浅,也启示我今后对“big data”保持敏感。
2019级传播学专业硕士研究生李同学:
邱林老师从田野调查、随机田野实验、自然实验三种方法入手,结合具体研究向我们清晰地展示了大数据驱动下社会科学研究的逻辑、成果和潜力,同时也指出了其中可能存在的陷阱。大数据在小样本之外提供了一种新的对数据理解的方式,并逐渐成为一种趋势。这提醒我们,在未来的学习研究中,要有意识地培养自己的数据意识和跨学科能力。
采写:郑秋、蔡亚纯、张昕妍
图片:同学提供
责编:操慧

